

The Power of Positive Reinforcement and Exploration
Reinforcement Learning in AI and Education

I’ve been fascinated for some time by clicker training. Originally used in marine animal training, the practice of using a clicking device and a reward when a desired behavior is performed has spread to human training too.
Clicker training originated as a direct application of B.F. Skinner's operant conditioning theory, with his students Marian and Keller Breland pioneering the method by reinforcing desired behaviors through rewards. By the 90s, it became popular to use with domesticated animals, especially through the book Don’t Shoot the Dog!
Clicker training is also used to train physical activities, such as in sports, though it’s usually given a different name. A gymnast practicing a handstand can get a click from the coach at the moment when proper form is achieved.
Clicker training provides a direct feedback signal that doesn’t have the perceived baggage of a human voice, so there’s less chance the learning signal will be overridden by other psychological factors. It’s a positive reinforcement because the scope of negative examples is infinite, and because a negative signal doesn’t define a path to success. The feedback is timely so the learner can understand success precisely, and so the learning signal is properly associated with the behavior.
No…I’m definitely not about to recommend clicker training in education. Nor am I going to say that reinforcement learning is the be all. It’s only one of the ways we learn.
I am bringing it up because reinforcement learning in AI requires similar principles be followed. Both clicker training and AI reinforcement learning work well and operate on the same fundamentals. The underlying principles of learning are not limited to biology.
As such, it’s an example of how AI literacy should not just be about how to use AI tools. It should be about the cross-cutting meta-principles behind how people and machines think and learn.
The Lessons from AI Reinforcement Learning
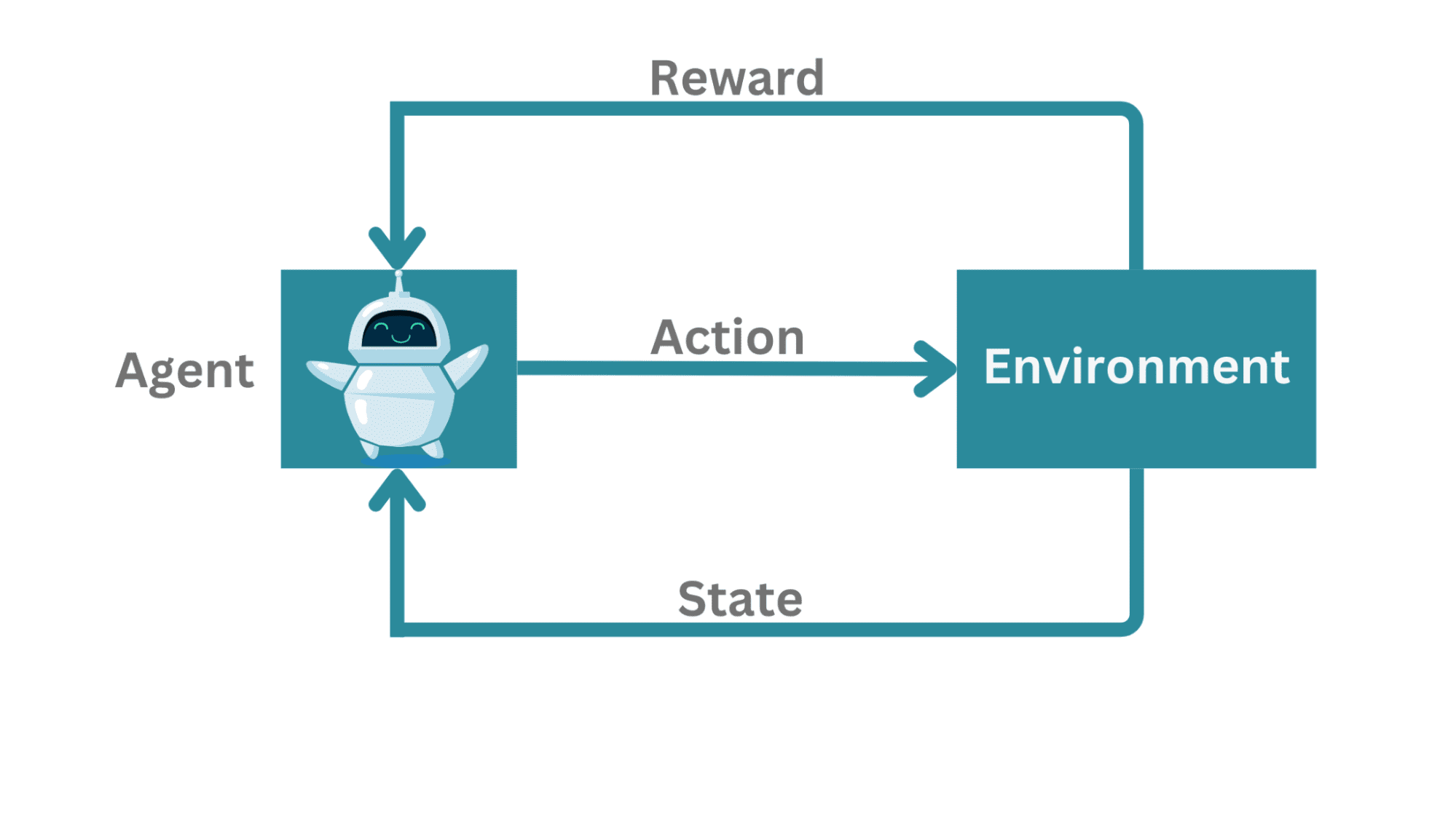
In AI, reinforcement learning (RL) is a method where agents learn to make decisions by performing actions and receiving feedback in the form of rewards. The AI agent aims to maximize cumulative rewards, learning optimal strategies through trial and error. This mirrors the principles of clicker training, where immediate, positive feedback reinforces desired behaviors.
AI developers use RL for experiential learning. It’s the preferred choice when the developer doesn’t have a giant dataset of examples with known right answers. Or when it’s not clear what are the characteristics of the environment AI will live in, or even what the task might be. This is often true in robotics, where the environment is unpredictable.
Similarly, AI models like ChatGPT use reinforcement learning to improve chain-of-thought processes and to incorporate the influence of human preference on what AI outputs. This enables them to generate coherent and relevant responses by learning from interactions rather than pre-defined data. Unlike what the clicker training analogy suggests, RL is also great when the environment gives delayed feedback, because a big part of its method is in figuring out policies for balancing short-term and long-term objectives, such as in playing chess.
The exploration-exploitation tradeoff is a fundamental concept in reinforcement learning (RL), where an AI must balance exploiting known rewarding actions and exploring new, potentially better strategies. Allowing an AI agent to explore its environment without immediate feedback can lead to more robust learning outcomes. Research has showed that agents equipped with curiosity-driven exploration performed better in complex environments by discovering novel states without relying solely on external rewards.
Adding negative reinforcement can sometimes hinder the learning process. Negative rewards may discourage exploration, causing the agent to avoid certain actions without understanding their potential long-term benefits. AI can sometimes find a clever way around negative reinforcement that is just a trick way to avoid the feedback. Negative feedback is a murkier signal. Excessive negative feedback can limit an agent's ability to discover optimal behaviors.
Therefore, encouraging exploration through positive reinforcement and minimizing negative feedback can enhance an agent's performance. By "playing around" without immediate penalties, the agent can gather valuable experiences that contribute to more effective decision-making in the long run.
Implications for the Classroom
Reinforcement learning is a human phenomenon too, operating under similar fundamental principles. Interestingly, both behaviorist and constructivist educational theories embody aspects of reinforcement learning, though they emphasize different elements of the process.
Behaviorist education theories, ala Skinner, emphasize the exploitation aspect of reinforcement learning, especially by focusing on the feedback (e.g., assessments). It has mostly been applied to training for precise, repeatable behaviors, with the result that pedagogies of spaced repetition are applied. Behaviorist pedagogies are often applied to problems that can be solved quickly, and the theory practically requires breaking complex problems into separate, small pieces. Problems requiring a sequence of judgment steps, or where it’s difficult to define success, or when it’s unclear what situations the learner will encounter, aren’t as easily addressed. Behaviorist curricula aren’t usually conducive to much student exploration.
Constructivist approaches encourage exploration, critical thinking, and knowledge construction through personal experience and reflection. Integrative challenges are more often posed. However, feedback is often delayed, infrequent, and hard to interpret. The process is slow and thus variation can be sacrificed; variation is key to future decisions about when a concept is useful.
While constructivist approaches emphasize exploration and personal discovery, they are most effective when paired with guidance and feedback. For example, when learning to read, students benefit from exploring texts but also need instruction on words and phonemes to build their skills efficiently. Exploration enriched by guidance accelerates learning.
I think the centuries long battle between behaviorists and constructivists is a bit like the debate over nature vs. nurture in biology. Both are trying to get at supporting brain learning modes (of which reinforcement learning is only one), but neither one do so very well on their own.
The more important fundamental, in this case, is reinforcement learning that should include both explore and exploit elements. Keeping that front-of-mind can aid decisions on pedagogy and assessment. Are those grades you’re giving out discouraging exploration? Do the examples students are working through demonstrate the boundaries of the concepts being explored? Is repetition better, or should the challenges be highly varied? Which examples are most valuable? Better understanding of the principles behind reinforcement learning for AI and people can improve such decisions.
AI literacy means more than just understanding how to use technological tools. It's about appreciating the underlying principles of learning, cognition, and interaction that are common to both humans and machines. The bonus is that those principles do help AI users use the tools more productively.
For educators, understanding these AI principles might also improve how educators think about their approaches. Both machines and humans benefit from balancing exploration and exploitation, timely feedback, and positive reinforcement. The more we understand about how learning works, the better we can structure human learning environments to encourage critical thinking, creativity, and adaptability.
©2024 Dasey Consulting LLC